情資有很多種,IP、HASH這類IOC常常被人提出,不過這類型比較適合與防禦系統整合即時更新。
這篇繼續整理一下常用網站,順便寫下程式方便自己使用
看一下最近大家都在搜尋哪個CVE,很大可能就是很有危害的(PS 也可以觀察自己公司或產業)
https://trends.google.com.tw/trends/explore?date=now%207-d&q=cve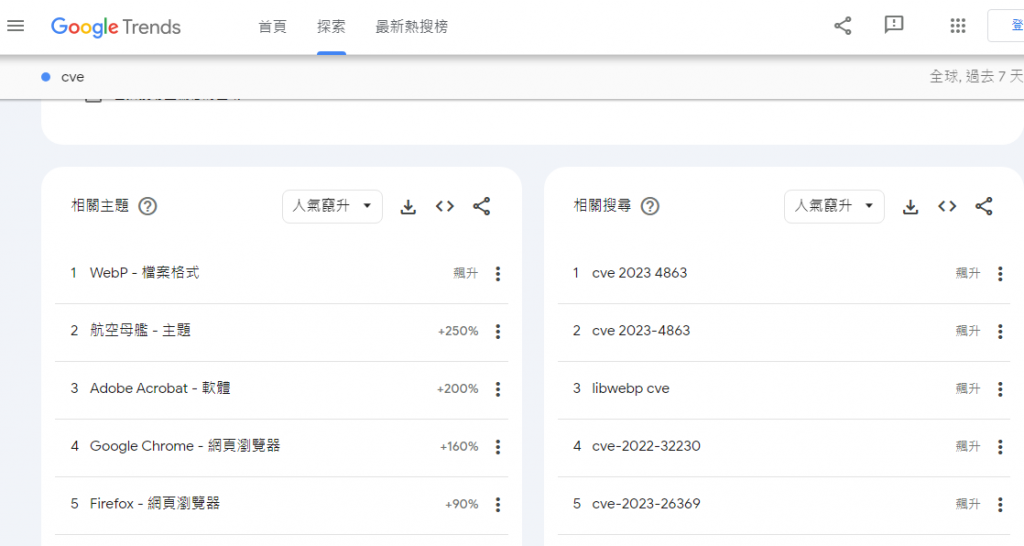
看一下是否有供應商中獎了
https://www.ransomlook.io/recent
https://www.redpacketsecurity.com/category/ransomware/
看一下有沒有人發資安重訊,順便了解一下市場狀況
https://mops.twse.com.tw/mops/web/t05st02
其實就算不懂程式開網頁也不會花太多時間,那程式的好處就是流程及標準化
!pip install pytrends
# 從pytrends庫導入TrendReq類
from pytrends.request import TrendReq
# 創建TrendReq對象,設置地區為en-US(美國英語)、時區為360
pytrends = TrendReq(hl='en-US', tz=360)
# 指定關鍵字列表,這裡只包含一個關鍵字"CVE"
kw_list = ["CVE"]
# 使用pytrends對象構建查詢,設置查詢參數
# - kw_list: 包含關鍵字的列表
# - cat: 查詢的類別,默認為0(所有類別)
# - timeframe: 查詢時間範圍,這裡是最近7天('now 7-d')
# - geo: 查詢地理位置,留空表示全球查詢
# - gprop: 查詢屬性,留空表示所有屬性
pytrends.build_payload(kw_list, cat=0, timeframe='now 7-d', geo='', gprop='')
# 執行相關查詢,並將結果存儲在data變量中
data = pytrends.related_queries()
data[kw_list[0]]['rising']

https://www.ransomlook.io/recent
import requests
from bs4 import BeautifulSoup
# 指定目標網站的URL
url = "請自行參考上面網址輸入"
# 發送HTTP GET請求並獲取網頁內容
response = requests.get(url)
# 檢查狀態碼,確保請求成功
if response.status_code == 200:
# 解析HTML內容
soup = BeautifulSoup(response.text, 'html.parser')
# 找到表格元素
table = soup.find('table')
# 提取表頭
thead = table.find('thead')
header_row = thead.find('tr')
headers = [header.text.strip() for header in header_row.find_all('th')]
# 提取表格數據
tbody = table.find('tbody')
rows = tbody.find_all('tr')
data = []
for row in rows:
columns = row.find_all('td')
row_data = [column.text.strip() for column in columns]
data.append(row_data)
# 印出表頭
print(headers)
# 印出表格數據
for row in data:
print(row)
else:
print(f"Failed to retrieve the webpage. Status code: {response.status_code}")
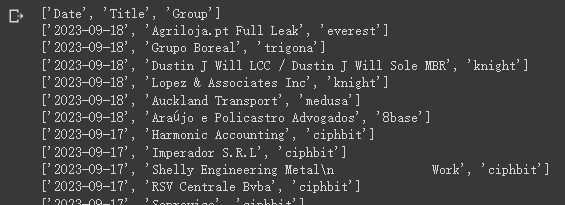
在戰場上情蒐真的是很重要的一塊,自己動手做過後在買商用情資的時候比較不會被坑,不好的情報會讓大家花了大把時間及金錢在錯的事情上。


 iThome鐵人賽
iThome鐵人賽